패스트캠퍼스 글 및 Elastic 가이드북을 읽고 정리하였습니다.
Elasticsearch 등장 배경
방대한 데이터를 가지고 있는 서비스에서 빠른 검색 플랫폼을 구축하는 것은 필수적이다. 일반적인 RDB에 대한 검색 속도는 O(N)이다. Elasticsearch는 해시 테이블 구조의 역색인 방식으로 데이터를 구축해놓기 때문에 검색 속도를 O(1)으로 단축한다. Elasticsearch가 가장 많이 활용되는 분야로는 상품 검색, 본문 검색, 매트릭 수집 및 분석, 로그 모니터링, 데이터 수집 및 분석과 추천이 있다. 이처럼 많은 영역에서 Elasticsearch가 활용되고 있는 것은 그만큼 쉬운 사용성과 높은 접근성 및 안정성, 확장성이 검증되었기 때문이다.
Elasticsearch의 장점
- 빠르고 효과적인 검색
- 역색인(Inverted Index)과 전문 검색(Full texted search) 기능을 지원한다.
- 대량 비정형 데이터 보관과 검색
- 기존 데이터베이스로는 처리하기 어려운 대량의 비정형 데이터 검색이 가능하며, 검색엔진이지만 mongoDB나 Hbase처럼 대용량 스토리지로 활용할 수 있다.
- 형태소 분석을 통한 자연어 처리
- 한국어는 복합어, 합성어 등 변형이 복잡한 언어인 형태소 분석기만 있으면 간편한 자연어 처리가 가능하다.
- 높은 확장성과 가용성
- Elasticsearch는 데이터를 샤드(Shard)라는 작은 단위로 나누어 제공한다. 데이터의 종류와 성격에 따라 데이터를 분산하여 빠르게 처리하기 때문에 확장성과 가용성이 높다.
- 자동완성 검색
- 초성검색
- 부분일치
- 한영 변환
- 오타 검색어 제안
역색인(Inverted Index) 방식

(출처: 티스토리)
- 키워드를 통해 문서를 찾아내는 방식
- 아주 빠른 전체 텍스트 검색이 가능하다.
- 문서에 나타나는 모든 고유한 단어 목록을 만들고, 각 단어가 발생하는 모든 문서를 식별한다.
- 해쉬 테이블 방식으로 검색시 O(1)의 성능을 낸다.
RDB vs Elasticsearch

- RDB
- PK, Index, 칼럼을 기준으로 순서대로 검색한다.
- 관계형 데이터베이스에서는 컬럼에다가 인덱스를 걸어 select하는데 있어 성능을 향상시킨다. 인덱스는 아래와 같은 b+tree 구조를 가지는 새로운 테이블을 하나 생성함으로 검색하는데 성능을 올려준다.
- 다만 인덱스가 걸려 있지 않은 컬럼에 대해서는 Full-Scan을 해버림으로 검색이 느려진다. 그렇다고 인덱스를 무분별하게 걸면 데이터베이스의 크기만 커지게 된다.

- Elasticsearch
- 본문의 검색어를 먼저 추출한 뒤 검색어에 해당하는 문서를 찾는다.
- 특정 단어가 어느 도큐먼트에 위치하는지 빠르게 찾아 낼 수 있음으로 관계형 데이터베이스보다 더 효율적으로 검색을 수행할 수 있다.
(출처: Slideshare,티스토리)
Elasticsearch 구조
- 인덱스(색인)
- 비슷한 특성을 가진 문서의 모음이다.
- 예) 영화 인덱스, 고객 인덱스, 주문 인덱스 등
- 도큐먼트
- 인덱스화할 수 있는 기본 정보 단위
- 예) 단일 영화 정보, 단일 고객 정보, 단일 주문 정보 등
RDB에 비유하자면 인덱스가 테이블(Table), 도큐먼트가 레코드(Record)라고 볼 수 있지 않을까?
- 샤드
- 인덱스를 분산 저장하는 저장소
- 복제본(Replica)
- 프라이머리 샤드(Primary Shard)를 복제하여 다른 노드에 저장한다.
- 샤드는 0개 이상의 복제본을 가질 수 있다.
- 각 노드는 하나 이상의 샤드를 관리한다.
- 같은 샤드와 복제본은 동일한 데이터를 담고 있으며 반드시 서로 다른 노드에 저장이 된다.
샤드와 복제본을 통해 데이터의 유실을 방지할 수 있다고 한다.

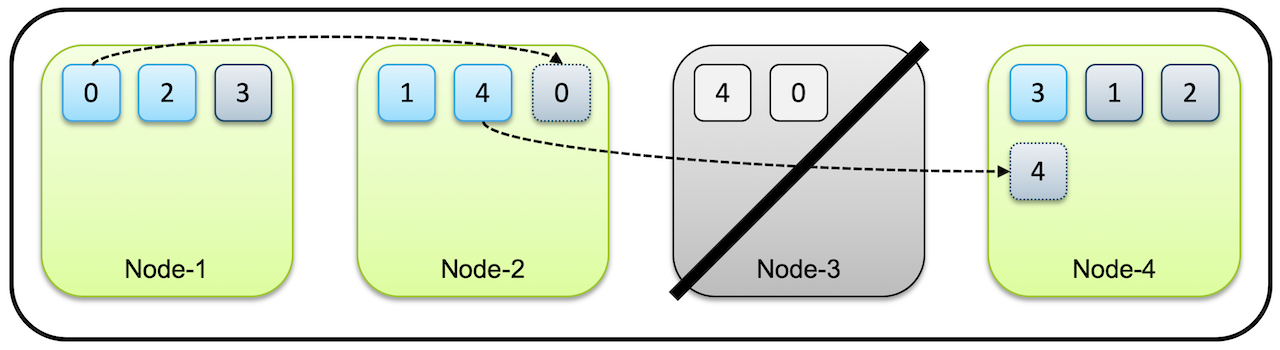
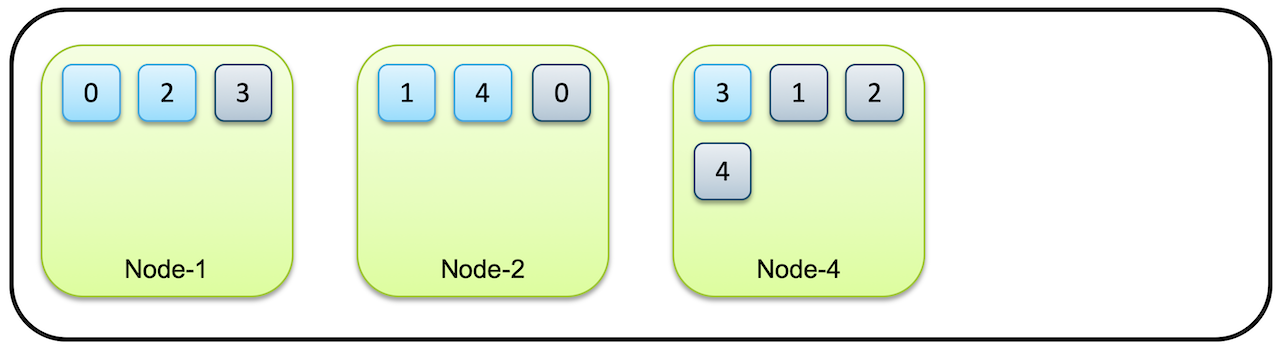
(사진 출처: elastic 가이드북)
처음에 클러스터는 먼저 유실된 노드가 복구 되기를 기다린다. 하지만 타임아웃이 지나 더 유실된 노드가 복구되지 않는다고 판단이 되면 Elasticsearch는 복제본이 사라져 1개만 남은 샤드들의 복제를 시작한다. 이렇게 프라이머리 샤드와 리플리카를 통해 Elasticsearch는 운영 중에 노드가 유실 되어도 데이터를 잃어버리지 않고 데이터의 가용성과 무결성을 보장한다. 프라이머리 샤드가 유실된 경우에는 새로 프라이머리 샤드가 생성되는 것이 아니라, 남아있던 복제본이 먼저 프라이머리 샤드로 승격이 되고 다른 노드에 새로 복제본을 생성하게 된다.
메인 DB로의 사용은 아직
여전히 데이터 삽입 시점에서의 데이터 유실 , 네트워크 단절시 스플릿 브레인(split brain) 으로 인한 데이터 유실이 발생할 수 있다. 또한 트랜잭션 ACID를 보장하지 못한다. 이 부분에 대해서 명확한 해결책을 찾기 전까지는 메인 디비로 사용하기 어렵다고 한다.
'Backend > 📬Server' 카테고리의 다른 글
| [Server] Redis와 서버 성능 개선을 위한 몇 가지 캐싱 전략들 (1) | 2021.11.29 |
|---|---|
| [Server] Websocket과 Stomp (0) | 2021.11.26 |
| [Server] CORS란? (0) | 2021.11.25 |
| [Server] OAuth와 JWT 도입하기 (0) | 2021.11.24 |
| [Server] RESTful API (0) | 2021.11.23 |



